
Kimi-Dev-72B: A open-source model for software engineering
Exploring Kimi-Dev-72B: A Breakthrough in Coding AI
Key Points
- Kimi-Dev-72B is an open-source coding model by Moonshot AI, likely excelling in software tasks.
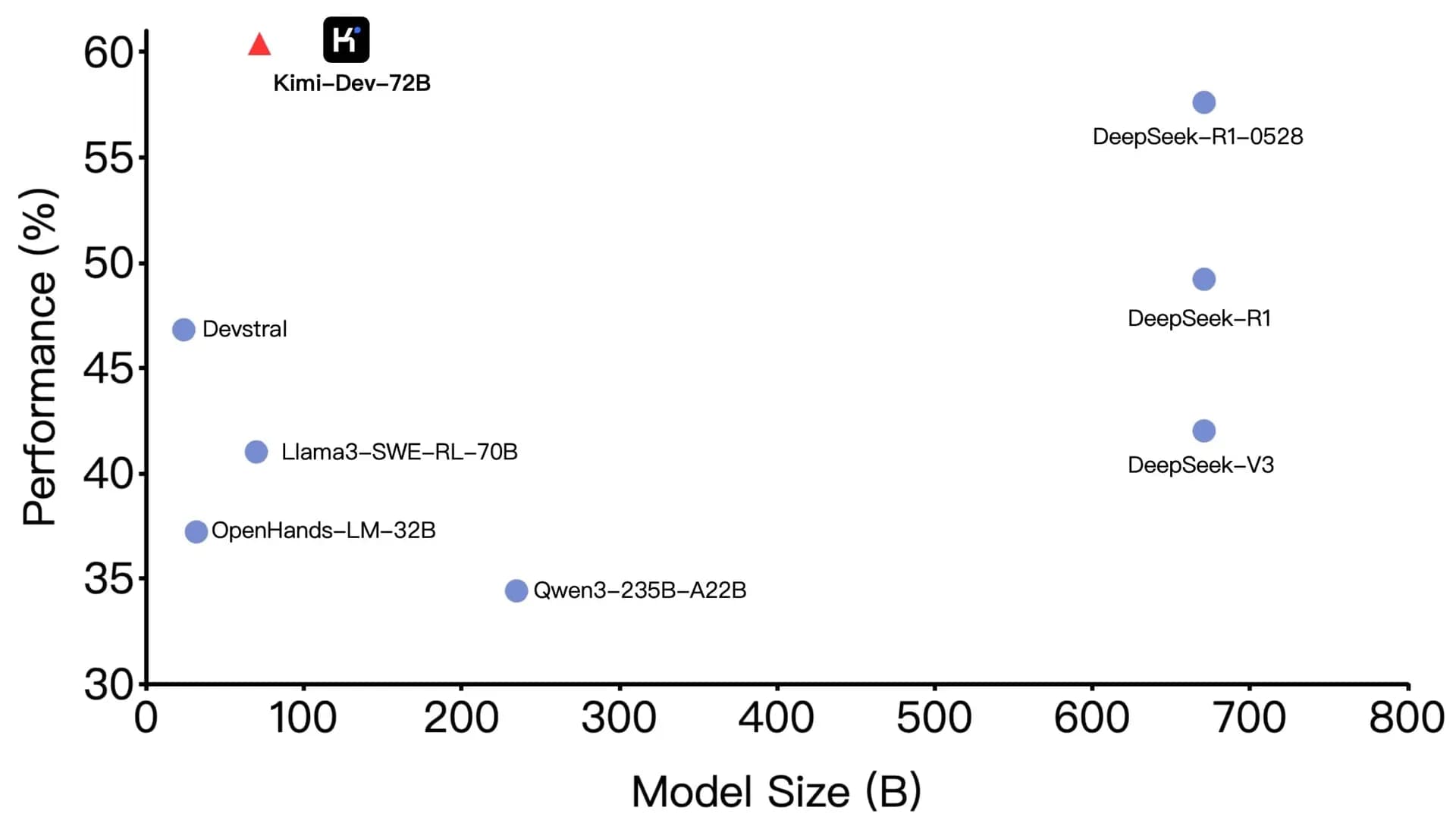
- It seems to perform well on SWE-bench Verified, with a reported 60.4% resolution rate among open-source models.
- Research suggests it’s great for debugging and code explanation, but real-world use may vary.
- The evidence leans toward it being slower and sometimes overthinking, affecting usability.
Introduction to Kimi-Dev-72B
Kimi-Dev-72B is a large language model (LLM) developed by Moonshot AI, designed specifically for software engineering tasks like coding and issue resolution. It’s open-source, meaning anyone can access and use it, which is great for developers and researchers. The model is based on Qwen2.5-72B and uses reinforcement learning to improve, focusing on patching real code repositories in Docker environments.
Performance and Benchmarks
It reportedly achieved a 60.4% resolution rate on SWE-bench Verified, a benchmark testing AI on real GitHub issues. This is impressive for open-source models, but some users note lower performance in different setups, suggesting results depend on how it’s used. For comparison, proprietary models like Claude-3-5-Sonnet scored 38.00% on a similar leaderboard, but exact comparisons are tricky due to setup differences.
Usage and Community Feedback
You can download Kimi-Dev-72B from Hugging Face or GitHub and deploy it using tools like vLLM. Community feedback is mixed: it’s praised for debugging and code explanation, but some find it slow and prone to overthinking, which might frustrate users. A YouTube video shows it in action, noting its strengths and weaknesses.
Potential Applications
It seems likely that Kimi-Dev-72B is best for tasks like automated bug fixing, code review, and generating test cases, making it a helpful tool for developers. However, testing in your specific context is recommended due to varying real-world performance.
Survey Note: Detailed Analysis of Kimi-Dev-72B
Overview and Background
Kimi-Dev-72B, developed by Moonshot AI, is an open-source large language model (LLM) fine-tuned for software engineering tasks, particularly coding and issue resolution. Released in mid-June 2025, it has garnered attention for its potential to revolutionize software development workflows. The model is based on Qwen2.5-72B and is optimized using large-scale reinforcement learning, a method that involves autonomously patching real repositories in Docker environments and rewarding only solutions that pass the entire test suite. This approach ensures alignment with real-world development standards, focusing on correctness and robustness.
The open-source nature of Kimi-Dev-72B, available under the MIT License, democratizes access for developers and researchers, encouraging community contributions and exploration. It can be accessed via Hugging Face and GitHub, with detailed installation and deployment instructions provided.
Technical Specifications
Kimi-Dev-72B is a 72-billion-parameter model, trained on 150 billion tokens, enhanced with real-world GitHub issues, pull request commits, and unit tests. Its reinforcement learning optimization involves applying code patches and validating them via full test suite execution, ensuring only correct and robust completions are rewarded. This training methodology is particularly suited for tasks requiring precise code manipulation, such as bug fixing and test case generation.
Suggested sampling parameters for optimal performance include a temperature of 0.7, top P of 0.8, and a repetition penalty of 1.05, as noted in community discussions. However, no official quantizations are provided by Moonshot AI, though community-generated GGUF quantizations (e.g., Q4KM) are available, which can affect performance on systems with limited VRAM.
Performance on Benchmarks
The model’s headline achievement is a 60.4% resolution rate on SWE-bench Verified, a benchmark evaluating AI models on resolving real-world GitHub issues from 500 human-validated samples. SWE-bench Verified, part of the broader SWE-bench ecosystem, tests systems’ ability to generate patches for issues, with evaluation performed by unit test verification using post-pull request behavior as the reference solution. This score positions Kimi-Dev-72B as the state-of-the-art among open-source models, surpassing the runner-up and setting a new benchmark as of June 2025.
However, comparisons with proprietary models reveal complexities. For instance, the HAL SWE-bench Verified leaderboard lists Claude-3-5-Sonnet at 38.00% and GPT-4o-2024-08-06 at 29.80%, both lower than Kimi-Dev-72B’s reported score. This discrepancy suggests potential differences in evaluation setups or agent configurations. Community feedback, particularly from X posts, indicates that while the benchmark score is high, real-world performance can drop significantly, with one user reporting only 17% accuracy when used in OpenHands, attributed to differences between agentic and agentless approaches.
Community Feedback and User Experiences
Community reactions, gathered from platforms like Reddit, X, and YouTube, are mixed. A YouTube video titled “Kimi-Dev-72B LOCAL Test (RooCode + LM Studio Coding & Debugging)” highlights its strengths in debugging and code explanation, attributing this to its reinforcement learning training on real GitHub issues. The video, with 2,947 views and 97 likes as of June 19, 2025, notes it’s best suited for these tasks rather than general code generation, but criticizes its slowness and tendency to overthink, impacting usability, especially on systems like two 3090 Ti GPUs with offloading to system RAM.
On Reddit, users expressed excitement for coding-focused models but raised concerns about overfitting to benchmarks, with some suggesting weaker daily use performance. An X post by @karminski3 on June 17, 2025, shared a practical test where Kimi-Dev-72B required multiple bug fixes to run a three.js demo, suggesting potential overfitting to SWE-bench. Conversely, @ai_for_success on the same day praised it as better than GPT-4.1 and just behind Gemini 2.5 Pro, reflecting the controversy around its real-world applicability.
Usage and Deployment
For practical use, Kimi-Dev-72B can be installed by cloning the repository from GitHub, creating a conda environment with Python 3.12, and installing dependencies via pip. Deployment is facilitated by vLLM, with commands like pip install vllm --extra-index-url https://download.pytorch.org/whl/cu128 for CUDA support, and serving via vllm serve Kimi-Dev-72B --served-model-name kimi-dev --host 0.0.0.0 --port 8000 --gpu-memory-utilization 0.95 --max-seq-len-to-capture 131072 --tensor-parallel-size 8. Rollout examples for bug fixing and test writing are provided, with preprocessed data available at a Google Drive link and example results in the repository.
Community contributions include GGUF quantizations by users like bullerwins, accessible at Hugging Face, though some users noted issues like hallucination in math and lack of guides for running, with thinking tokens causing compatibility issues with tools like openwebui.
Potential Applications and Limitations
Given its training, Kimi-Dev-72B is particularly suited for automated bug fixing, code review, explanation, and test case generation, aligning with its reinforcement learning focus on real-world GitHub issues. A Medium article by Frank Morales Aguilera, published on June 18, 2025, at Medium, explores its versatility, noting capabilities in generating clean, well-documented Python code and handling subjective queries like identifying Cuban poets. It also suggests potential in flight planning AI, integrating meteorological data and air traffic rules, though this is speculative.
Limitations include slower token generation and overthinking, as seen in the YouTube video, and varying performance across different frameworks, as evidenced by the OpenHands test. Users are advised to test it in their specific contexts, considering hardware constraints like VRAM (56GB recommended for 72B model) and potential need for dynamic quantizations, as requested by community members.
Comparative Analysis
While Kimi-Dev-72B leads among open-source models, comparisons with proprietary models are complex due to evaluation differences. The HAL leaderboard, as of earlier 2025 data, shows lower scores for proprietary models, but community discussions suggest Kimi-Dev-72B’s high benchmark score may not translate universally, with some users comparing it unfavorably to models like DeepSeek R1 or Qwen3 235B in daily use. This highlights the need for context-specific evaluation, with ongoing discussions on X and Reddit reflecting both optimism and skepticism.
Tables of Key Metrics
Below is a table summarizing key performance metrics and community feedback:
| Metric | Details |
|---|---|
| Model Size | 72B parameters, 150B tokens trained |
| SWE-bench Verified Score | 60.4% (open-source SOTA, June 2025) |
| Base Model | Qwen2.5-72B |
| Training Method | Reinforcement learning, Docker-based patching |
| Community Feedback | Strong in debugging, slow, may overthink |
| Hardware Requirement | 56GB VRAM recommended for full precision |
Another table for comparison with top models on SWE-bench Verified, based on available data:
| Rank | Model | Accuracy (%) | Cost ($) | Notes |
|---|---|---|---|---|
| 1 | Kimi-Dev-72B (Reported) | 60.4 | - | Open-source, June 2025 release |
| - | Claude-3-5-Sonnet | 38.00 | 67.09 | Proprietary, HAL leaderboard |
| - | GPT-4o-2024-08-06 | 29.80 | 79.84 | Proprietary, HAL leaderboard |
Note: The HAL leaderboard data may not reflect the latest updates, and Kimi-Dev-72B’s score is based on Moonshot AI’s announcement, with potential variations in real-world use.
Conclusion
Kimi-Dev-72B stands as a pioneering open-source model for software engineering, with a reported 60.4% on SWE-bench Verified, positioning it as a leader among open-source LLMs. Its reinforcement learning approach and focus on real-world GitHub issues make it a valuable tool for developers, particularly for debugging and code explanation. However, real-world performance varies, with community feedback highlighting slowness and overthinking, and lower accuracy in some setups. As of June 19, 2025, it remains a promising but context-dependent solution, with ongoing community efforts to enhance usability and address limitations.